Difference Between Dense Index and Sparse Index in DBMS
Last Updated :
20 Dec, 2023
Indexing is a technique in DBMS that is used to optimize the performance of a database by reducing the number of disk access required. An index is a type of data structure. With the help of an index, we can locate and access data in database tables faster. The dense index and Sparse index are two different approaches to organizing and accessing data in the data structure. These are commonly used in databases and information retrieval systems.

Index structure
Different Types of Indexing Methods
Indexing methods in a database management system (DBMS) can be classified as dense or sparse indexing methods, depending on the number of index entries in the database. Let’s take a look at the differences between the two types of indexing methods:
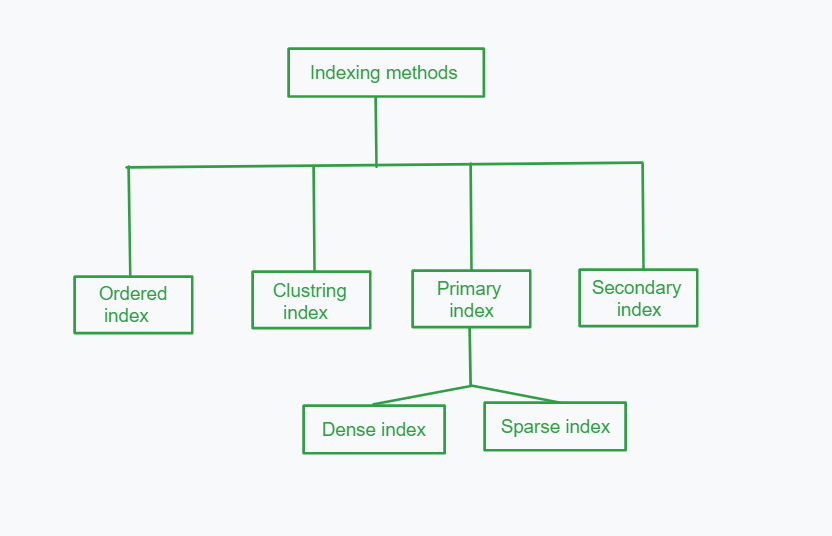
Types of index
Dense indexing and Sparse indexing are types of primary indexing. Now let’s take an overview of these terms:
Dense Index
It contains an index record for every search key value in the file. This will result in making searching faster. The total number of records in the index table and main table are the same. It will result in the requirement for more space to store the index of records itself.

Dense indexing
Advantages
- Gives quick access to records, particularly for Small datasets.
- Effective for range searches since each key value has an entry.
Disadvantages
- Can be memory-intensive and may require a significant amount of storage space.
- Insertions and deletions result in a higher maintenance overhead because the index must be updated more frequently.
Sparse Index
Sparse index contains an index entry only for some records. In the place of pointing to all the records in the main table index points records in a specific gap. This indexing helps you to overcome the issues of dense indexing in DBMS.

Sparse indexing
Advantages
- Uses less storage space than thick indexes, particularly for large datasets.
- Lessens the effect that insertions and deletions have from index maintenance operations.
Disadvantages
- Since there may not be an index entry for every key value, access may involve additional steps.
- might not be as effective as dense indexes for range queries.
Difference Between Dense Index and Sparse Index
|
The index size is larger in dense index.
|
In sparse index, the index size is smaller.
|
|
Time to locate data in index table is less.
|
Time to locate data in index table is more.
|
|
There is more overhead for insertions and deletions in dense index.
|
Sparse indexing have less overhead for insertions and deletions.
|
|
Records in dense index need not to be clustered.
|
In case of sparse index, records need to be clustered.
|
|
Computing time in RAM (Random access memory) is less with dense index.
|
In sparse index, computing time in RAM is more.
|
|
Data pointers in dense index point to each record in the data file.
|
In sparse index, data pointers point to fewer records in data file.
|
|
Search performance is generally faster in dense index.
|
In sparse index, search performance may require additional steps, which will result in slowing down the process.
|
Conclusion
In conclusion, we can say that the choice between dense and sparse indexing depends on data structure requirements. Dense indexing have advantages of direct access. Sparse indexing have advantages of memory efficiency and less overheads for insertions and deletions.
Please Login to comment...