Count the nodes of a tree whose weighted string does not contain any duplicate characters
Last Updated :
06 Mar, 2023
Given a tree, and the weights (in the form of strings) of all the nodes, the task is to count the nodes whose weights do not contain any duplicate character.
Examples:
Input:
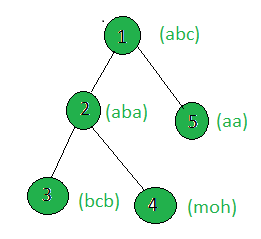
Output: 2
Only the strings of the node 1 and 4 contains unique strings.
Approach: Perform dfs on the tree and for every node, check if its string contains duplicate char or not, If not then increment the count.
Below is the implementation of the above approach:
C++
#include <bits/stdc++.h>
using namespace std;
int cnt = 0;
vector<int> graph[100];
vector<string> weight(100);
bool uniqueChars(string x)
{
unordered_map<char, int> mp;
int n=x.size();
for (int i = 0; i < n; i++){
mp[x[i]]++;
if(mp[x[i]]>1)return false;
}
return true;
}
void dfs(int node)
{
if (uniqueChars(weight[node]))
cnt += 1;
for (int to : graph[node]) {
dfs(to);
}
}
int main()
{
weight[1] = "abc";
weight[2] = "aba";
weight[3] = "bcb";
weight[4] = "moh";
weight[5] = "aa";
graph[1].push_back(2);
graph[2].push_back(3);
graph[2].push_back(4);
graph[1].push_back(5);
dfs(1);
cout << cnt;
return 0;
}
|
Java
import java.util.*;
class GFG
{
static int cnt = 0;
static Vector<Integer>[] graph = new Vector[100];
static String[] weight = new String[100];
static boolean uniqueChars(char[] arr)
{
HashMap<Character, Integer> mp =
new HashMap<Character, Integer>();
int n = arr.length;
for (int i = 0; i < n; i++){
if (mp.containsKey(arr[i]))
{
return false;
}
else
{
mp.put(arr[i], 1);
}
}
return true;
}
static void dfs(int node)
{
if (uniqueChars(weight[node].toCharArray()))
cnt += 1;
for (int to : graph[node])
{
dfs(to);
}
}
public static void main(String[] args)
{
for (int i = 0; i < 100; i++)
graph[i] = new Vector<Integer>();
weight[1] = "abc";
weight[2] = "aba";
weight[3] = "bcb";
weight[4] = "moh";
weight[5] = "aa";
graph[1].add(2);
graph[2].add(3);
graph[2].add(4);
graph[1].add(5);
dfs(1);
System.out.print(cnt);
}
}
|
Python3
cnt = 0
graph = [[] for i in range(100)]
weight = [0] * 100
def uniqueChars(x):
mp = {}
n = len(x)
for i in range(n):
if x[i] not in mp:
mp[x[i]] = 0
else:
return False
mp[x[i]] += 1
return True
def dfs(node):
global cnt, x
if (uniqueChars(weight[node])):
cnt += 1
for to in graph[node]:
dfs(to)
x = 5
weight[1] = "abc"
weight[2] = "aba"
weight[3] = "bcb"
weight[4] = "moh"
weight[5] = "aa"
graph[1].append(2)
graph[2].append(3)
graph[2].append(4)
graph[1].append(5)
dfs(1)
print(cnt)
|
C#
using System;
using System.Collections.Generic;
class GFG
{
static int cnt = 0;
static List<int>[] graph = new List<int>[100];
static String[] weight = new String[100];
static bool uniqueChars(char[] arr)
{
Dictionary<char, int> mp =
new Dictionary<char, int>();
int n = arr.Length;
for (int i = 0; i < n; i++)
if (mp.ContainsKey(arr[i]))
{
return false;
}
else
{
mp.Add(arr[i], 1);
}
return true;
}
static void dfs(int node)
{
if (uniqueChars(weight[node].ToCharArray()))
cnt += 1;
foreach (int to in graph[node])
{
dfs(to);
}
}
public static void Main(String[] args)
{
for (int i = 0; i < 100; i++)
graph[i] = new List<int>();
weight[1] = "abc";
weight[2] = "aba";
weight[3] = "bcb";
weight[4] = "moh";
weight[5] = "aa";
graph[1].Add(2);
graph[2].Add(3);
graph[2].Add(4);
graph[1].Add(5);
dfs(1);
Console.Write(cnt);
}
}
|
Javascript
<script>
let cnt = 0;
let graph = new Array();
for (let i = 0; i < 100; i++) {
graph.push([])
}
let weight = new Array(100);
function uniqueChars(x) {
let mp = new Map();
let n = x.length;
for (let i = 0; i < n; i++) {
if (mp.has(x[i])) {
return false;
} else {
mp.set(x[i], 1)
}
}
return true;
}
function dfs(node) {
if (uniqueChars(weight[node]))
cnt += 1;
for (let to of graph[node]) {
dfs(to);
}
}
weight[1] = "abc";
weight[2] = "aba";
weight[3] = "bcb";
weight[4] = "moh";
weight[5] = "aa";
graph[1].push(2);
graph[2].push(3);
graph[2].push(4);
graph[1].push(5);
dfs(1);
document.write(cnt);
</script>
|
Complexity Analysis:
- Time Complexity: O(N*Len) where Len is the maximum length of the weighted string of a node in the given tree.
In dfs, every node of the tree is processed once and hence the complexity due to the dfs is O(N) if there are total N nodes in the tree. Also, processing of every node involves traversing the weighted string of that node thus adding a complexity of O(Len) where Len is the length of the weighted string. Therefore, the time complexity is O(N*Len).
- Auxiliary Space: O(1).
Any extra space is not required, so the space complexity is constant.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...