Extract all the URLs from the webpage Using R Language
Last Updated :
18 Mar, 2022
In this article, we will learn how to scrap all the URLs from the webpage using the R Programming language.
To scrap URLs we will be using httr and XML libraries. We will be using httr package to make HTTP requestsXML and XML to identify URLs using xml tags.
- httr library is used to make HTTP requests in R language as it provides a wrapper for the curl package.
- XML library is used for working with XML files and XML tags.
Installation:
install.packages(“httr”)
install.packages(“XML”)
After installing the required packages we need to import httr and XML libraries and create a variable and store the URL of the site. Now we will be using GET() of httr packages to make HTTP requests, so we have raw data and we need to convert it in HTML format which can be done by using htmlParse()the
We have successfully scrapped HTML data but we only need URLs so to scrap URL we xpathSApply() and pass the HTML data to it, We have not yet completed now we have to pass XML tag to it so that we can get everything related to that tag. For URLs, we will “href” tag which is used to declare URLs.
Note: You need not use install.packages() if you have already installed the package once.
Stepwise Implementation
Step 1: Installing libraries:
R
install.packages("httr")
install.packages("XML")
|
Step 2: Import libraries:
R
library(httr)
library(XML)
|
Step 3: Making HTTP requests:
In this step, we will pass our URL in GET() to request site data and store the returned data in the resource variable.
Step 4: Parse site data in HTML format:
In this step, we parsed the data to HTML using htmlparse().
R
parse<-htmlParse(resource)
|
Step 5: Identify URLs and print them:
In this step, we used to xpathSApply() to locate URLs.
R
links<-xpathSApply(parse,path = "//a",xmlGetAttr,"href")
print(links)
|
We know <a> tag is used to define URL and it is stored in href attribute.
<a href=”url”></a>
So xpathSApply() will find all the <a> tags and scrap the link stored in href attribute. And then we will store all the URLs in a variable and print it.
Example:
R
install.packages("httr")
install.packages("XML")
library(httr)
library(XML)
resource < -GET(url)
parse < -htmlParse(resource)
links < -xpathSApply(parse, path="//a", xmlGetAttr, "href")
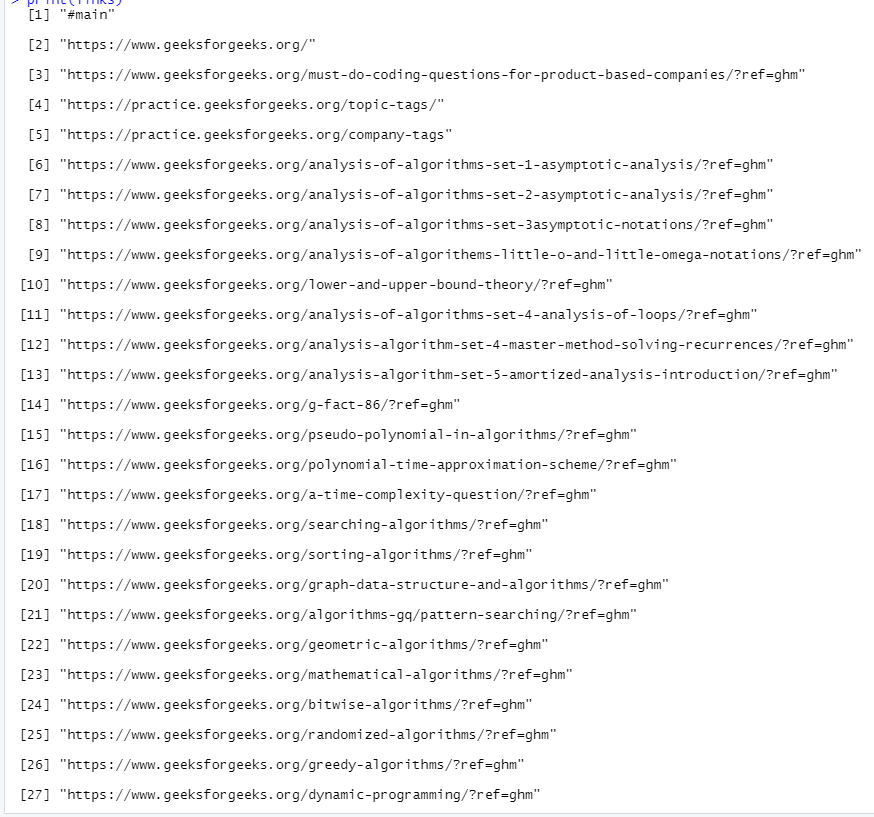
print(links)
|
Output:
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...