How to Return Random Rows Efficiently in SQL Server?
Last Updated :
25 Jan, 2022
In this article, we are going to learn an SQL Query to return random rows efficiently. To execute the query, we are going to first create a table and add data into it. We will then sort the data according to randomly created IDs(using the NEWID() method) and return the top rows after the sorting operations. We are printing data here so we would use the “SELECT command” in SQL.
NEWID():
NEWID( ) is a SQL function that is used to generate a random unique value of type unique identifier.
Step 1: New Database creation
To make a new database creation, the following query can be used:
Query:
CREATE DATABASE random_sql;

Step 2: Specifying the database in use
We need to specify in which database we are going to do operations. The query to use a Database is :
Query:
USE random_sql;

Step 3: New table creation
To create a new table we will use the following query:
Query:
CREATE TABLE random_table(
col1 INT,
col2 VARCHAR(100));

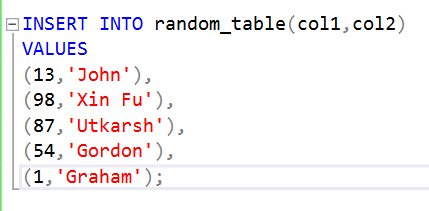
Step 4 : Data insertion
To insert data into the table, the following query will be used:
Query:
INSERT INTO random_table(col1,col2)
VALUES
(13,'John'),
(98,'Xin Fu'),
(87,'Utkarsh'),
(54,'Gordon'),
(1,'Graham');
Step 5: Selecting random data
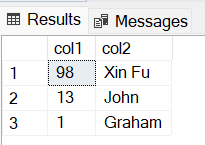
In this step, we create final query by using the SELECT TOP clause. This clause is used to fetch limited number of rows from a database. The rows returned would be made random by an operation on the table. We assign a random ID to all rows and sort the rows according to the created ID, thus giving us a randomly sorted table to extract data. For this we use ORDER BY NEWID().
SELECT TOP 3 *
FROM random_table
ORDER BY NEWID();

Output:
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...