Python | Pandas dataframe.rsub()
Last Updated :
24 Nov, 2018
Python is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric python packages. Pandas is one of those packages and makes importing and analyzing data much easier.
Pandas dataframe.rsub() function is used for finding the subtraction of dataframe and other, element-wise (binary operator rfloordiv). This function is essentially same as doing other – dataframe but with a support to substitute for missing data in one of the inputs.
Syntax:DataFrame.rsub(other, axis=’columns’, level=None, fill_value=None)
Parameters :
other : Series, DataFrame, or constant
axis : For Series input, axis to match Series index on
level : Broadcast across a level, matching Index values on the passed MultiIndex level
fill_value : Fill existing missing (NaN) values, and any new element needed for successful DataFrame alignment, with this value before computation. If data in both corresponding DataFrame locations is missing the result will be missing.
Returns : result : DataFrame
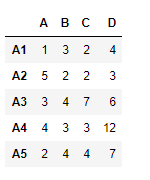
Example #1: Use rsub() function to subtract each element of a series to a corresponding value in a dataframe over the column axis.
import pandas as pd
df = pd.DataFrame({"A":[1, 5, 3, 4, 2],
"B":[3, 2, 4, 3, 4],
"C":[2, 2, 7, 3, 4],
"D":[4, 3, 6, 12, 7]},
index =["A1", "A2", "A3", "A4", "A5"])
df
|
Let’s create the series
import pandas as pd
sr = pd.Series([12, 25, 64, 18], index =["A", "B", "C", "D"])
sr
|

Lets use the dataframe.rsub() function to subtract each element in a series with the corresponding element in the dataframe.
Output :
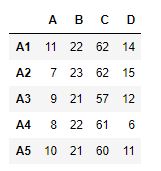
Example #2: Use rsub() function to subtract each element in a dataframe with the corresponding element in other dataframe
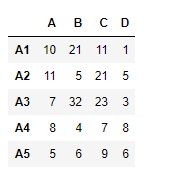
import pandas as pd
df1 = pd.DataFrame({"A":[1, 5, 3, 4, 2],
"B":[3, 2, 4, 3, 4],
"C":[2, 2, 7, 3, 4],
"D":[4, 3, 6, 12, 7]},
index =["A1", "A2", "A3", "A4", "A5"])
df2 = pd.DataFrame({"A":[10, 11, 7, 8, 5],
"B":[21, 5, 32, 4, 6],
"C":[11, 21, 23, 7, 9],
"D":[1, 5, 3, 8, 6]},
index =["A1", "A2", "A3", "A4", "A5"])
print(df1)
print(df2)
|
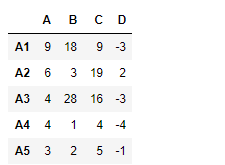
Lets perform df2 - df1
Output :
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...