ALBERT – A Light BERT for Supervised Learning
Last Updated :
27 Jan, 2022
The BERT was proposed by researchers at Google AI in 2018. BERT has created something like a transformation in NLP similar to that caused by AlexNet in computer vision in 2012. It allows one to leverage large amounts of text data that is available for training the model in a self-supervised way.
ALBERT was proposed by researchers at Google Research in 2019. The goal of this paper to improve the training and results of BERT architecture by using different techniques like parameter sharing, factorization of embedding matrix, Inter sentence Coherence loss.
Model architecture:
The backbone of ALBERT architecture is similar to BERT that is encoder layers with GELU (Gaussian Error Linear Unit) activation function. However, below are the three main changes that are present in ALBERT but not in BERT.
- Factorization of the Embedding matrix: In the BERT model and its improvements such as XLNet and ROBERTa, the input layer embeddings and hidden layer embeddings have the same size. But in this model, the authors separated the two embedding matrices. This is because input-level embedding (E) needs to refine only context-independent learning but hidden level embedding (H) requires context-dependent learning. This step leads to a reduction in parameters by 80% with a minor drop in performance when compared to BERT.
- Cross-layer parameter sharing: The authors of this model also proposed the parameter sharing between different layers of the model to improve efficiency and decrease redundancy. The paper proposed that since the previous versions of BERT, XLNet, and ROBERTa have encoder layer stacked on top of one another causes the model to learn similar operations on different layers. The authors proposed three types of parameter sharing in this paper:
- Only share Feed Forward network parameter
- Only share attention parameters
- Share all parameters. Default setting used by authors unless stated otherwise.
The above step leads to a 70% reduction in the overall number of parameters.
- Inter Sentence Coherence Prediction: Similar to the BERT, ALBERT also used Masked Language model in training. However, Instead of using NSP (Next Sentence Prediction) loss, ALBERT used a new loss called SOP (Sentence Order Prediction). NSP is a binary classification loss for predicting whether two segments appear consecutively in the original text, the disadvantage of this loss is that it checks for coherence as well as the topic to identify the next sentence. However, the SOP only looks for sentence coherence.
ALBERT is released in 4 different model sizes,
| Model |
Size |
Parameters |
Encoder Layers (L) |
Embedding (E) |
Hidden units (H) |
| BERT |
Base |
108 M |
12 |
768 |
768 |
| Large |
334 M |
24 |
1024 |
1024 |
| ALBERT |
Base |
12 M |
12 |
128 |
768 |
| Large |
18 M |
24 |
128 |
1024 |
| X Large |
60 M |
24 |
128 |
2048 |
| XX Large |
235 M |
12 |
128 |
4096 |
As we can see from the above table is the ALBERT model has a smaller parameter size as compared to corresponding BERT models due to the above changes authors made in the architecture. For Example, BERT base has 9x more parameters than the ALBERT base, and BERT Large has 18x more parameters than ALBERT Large.
Dataset used:
Similar to the BERT, ALBERT is also pre-trained on the English Wikipedia and Book CORPUS dataset which together contains 16 GB of uncompressed data.
Implementation:
- In this implementation, we will use a pre-trained ALBERT model using TF-Hub and ALBERT GitHub repository. We will run the model on Microsoft Research Paraphrase Corpus (MRPC) dataset on GLUE benchmark.
Python3
! git clone https://github.com/google-research/albert
! pip install -r albert/requirements.txt
! test -d download_glue_repo ||
git clone https://gist.github.com/60c2bdb54d156a41194446737ce03e2e.git glue_repo
!python glue_repo/download_glue_data.py --data_dir=/content/MRPC --tasks='MRPC'
!python -m albert.run_classifier \
--data_dir=MRPC/ \
--output_dir=output/ \
--albert_hub_module_handle=$ALBERT_MODEL_HUB \
--spm_model_file="from_tf_hub" \
--do_train=False \
--do_eval=True \
--do_predict=True \
--max_seq_length=512 \
--optimizer=adamw \
--task_name=MRPC \
--warmup_step=200 \
--learning_rate=2e-5 \
--train_step=800 \
--save_checkpoints_steps=100 \
--train_batch_size=32
|
Results & Conclusion:
Despite the much fewer number of parameters, ALBERT has achieved the state-of-the-art of many NLP tasks. Below are the results of ALBERT on GLUE benchmark datasets. The ALBER

ALBERT results as compared to other models on GLUE benchmark.
Below are the results of the ALBERT-xxl model on SQuAD and RACE benchmark datasets.
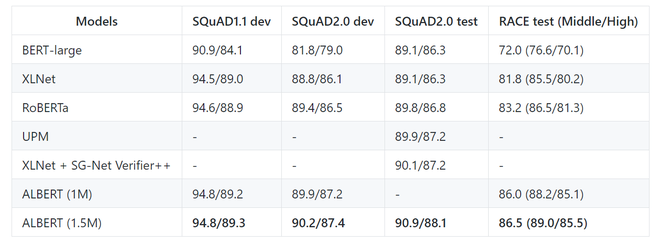
Here, ALBERT (1M) represents model is trained with 1M steps whereas, ALBERT 1.5M represents the model is trained with 1.5M epoch.
As of now, the authors have also released a new version of ALBERT (V2), with improvement in the average accuracy of the BASE, LARGE, X-LARGE model as compared to V1.
| Version |
Size |
Average Score |
| ALBERT V2 |
Base |
82.3 |
| Large |
85.7 |
| X-Large |
87.9 |
| XX-Large |
90.9 |
| ALBERT V1 |
Base |
80.1 |
| Large |
82.4 |
| X-Large |
85.5 |
| XX-Large |
91.0 |
References:
Share your thoughts in the comments
Please Login to comment...