What Is AWS Data Pipeline ?
Last Updated :
23 Apr, 2024
Companies and associations are evolving through time and their growing phases resulting in various forms of data creation, transformation, and transfers. The process of gathering, testing verifying, and distributing data helps in the expansion of Organization advancements. Amazon Web Service (AWS) is the perfect platform for enlarging extensive access on a global scale. AWS Data pipeline is designed to accelerate data transfers from one source to a specified destination. Data operations like repetitive and continuous can be performed quickly at a lower cost by using data channels.
What Is A Data Channel?
A Data Channel is a medium of moving data from one position (source) to a destination (similar to a data storehouse). In the process, the data is converted and optimized to gain a state that can be used and anatomized to develop business ideas. A data channel is a stage involved in aggregating, organizing, and moving data. Ultramodern data channels automate numerous of the homemade ways involved in transforming and optimizing nonstop data loads. The set of processes of data movement and transformation organized in the data channel (route/pathway) is known as Data pipeline.
Components of AWS Data Pipeline
The following are the main factors of the AWS Data Pipeline :
The AWS Data Pipeline Definition specifies on how business teams should communicate with the Data Pipeline. It contains different information:
- Data Nodes: These specify the name, position, and format of the data sources similar to Amazon S3, Dynamo DB, etc.
- Conditioning: Conditioning is the conduct that performs the SQL Queries on the databases, and transforms the data from one data source to another data source.
- Schedules: Scheduling is performed on the Conditioning.
- Preconditions: Preconditions must be satisfied before cataloging the conditioning. For illustration, if you want to move the data from Amazon S3, also precondition is to check whether the data is available in Amazon S3 or not.
- Facility: You have Resources similar to Amazon EC2 or EMR cluster.
- Conduct: It updates the status of your channel similar to transferring a dispatch to you or sparking an alarm.
- Pipeline factors: We’ve formerly bandied about the pipeline factors. It is principally how you communicate your Data Pipeline to the AWS services.
- Cases: When all the pipeline factors are collected in a channel(pipeline), also it creates a practicable case that contains the information of a specific task.
- Attempts: Data Pipeline allows, retrying the operations which are failed. These are nothing but Attempts.
- Task Runner: Task Runner is an operation that does the tasks from the Data Pipeline and performs the tasks.
What Is AWS Data Pipeline?
AWS Data Pipeline is a web service that helps you reliably process and move data between different AWS compute and storage services, as well as on-premises data sources, at specified intervals. With AWS Data Pipeline you can easily access data from the location where it is stored, transform & process it at scale, and efficiently transfer the results to AWS services such as Amazon S3, Amazon RDS, Amazon DynamoDB, and Amazon EMR. It allows you to create complex data processing workloads that are fault-tolerant, repeatable, and highly available.
How Does A Data Pipeline Work?
Fundamentally, a Data pipeline functions as a efficiently way of transporting and improving of data from its origin to specified destination of storage or analysis. The architecture of data pipeline dealing with the following critical components.

Why Do We Need A Data Pipeline?
In this modern age, A large volumes of data is increasing and it raise the complexity issues in the handling and management of growing data. Services like AWS Data pipeline plays significant role in processing and storing of data in variety of formats. This datapipeline act as essential component in protecting data quality, automating operations and accelerating procedures. It provides modern data customizations in organizing framework and gaining business gain with having useful insights from their data assets.
Accessing AWS Data Pipeline
AWS Data Pipeline can be accessible and manageable through various interfaces for supporting different preferences and needs. The following are the some of the main accessing way of AWS Data pipeline:
- AWS Management Console: It is web based accessing way of AWS data pipeline. In this we have to use web-based interface of the AWS management console for creating, accessing and managing your pipelines visually. It provides user-friendly experience for interacting with AWS Data pipeline.
- AWS Command Line Interface ( CLI ): It is CLI mode of accessing AWS Data Pipeline, it provides more options and functionalities compared WebUI, one who is comfortable with command line interfaces can go for it. It is supported on Linux, Windows and MacOS with offering flexible and efficiency in managing pipelines through scripts and commands.
- AWS SDKs: It is API based way of accessing AWS Data Pipeline used by developers. It provides enhancing language-specific APIs that are provided by AWS SDKs for programmatically interaction. These SDKs handles various connection details such as request signing, error handling, making integration into applications smoother and more efficient.
- Query API: It is one of the way that is used for direct and low level accessing to AWS DataPipeline. The Query API offers HTTPs based APIs that are triggered through https requests. When we are implementing more complex one, it provides the granular control over the pipeline management and operation for application requirement and customiziation.
How To Create AWS Data Pipeline: A Step-By-Step Guide
Accessing of AWS Data Pipeline involves several key steps those discussed as follows. Here we discussed an effective and streamlined workflow of data processing.
Step 1: Login To AWS Console
- Firstly, login in to your AWS Console and login with your credentials such as username and password.

Step 2: Navigate to Data Pipeline
- After login in, you will be landed into Console Home. From their, search for DataPipeline service in search bar and redirect to that page.
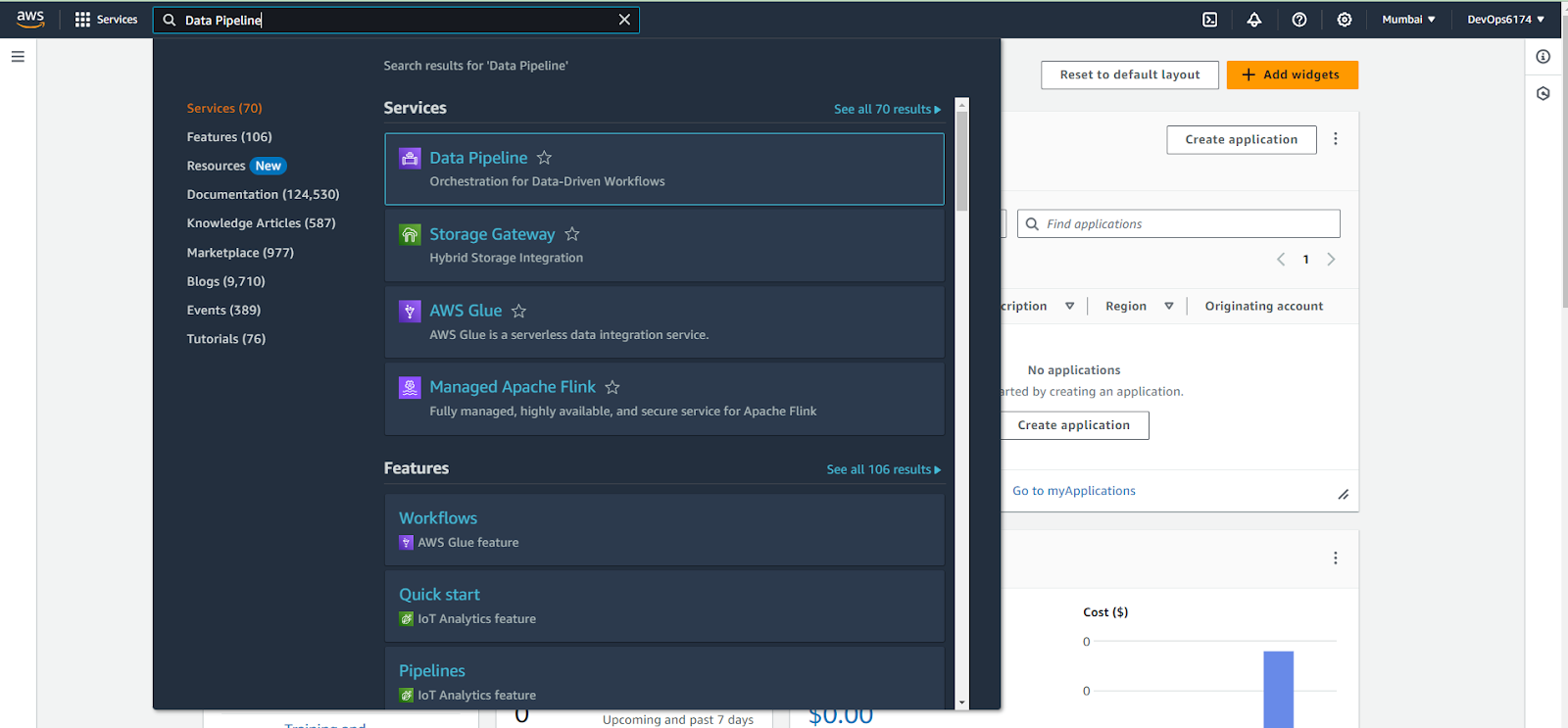
Step 3: Create or Select Pipeline
- After directing to the Data Pipeline page, now create a new pipeline or select an existing one from the list of pipelines displayed in the console.
Step 4: Define Pipeline Configuration
- Define the configuration of the pipeline by specifying the data sources, activities, schedules and resources that are needed and define them as per requirements.
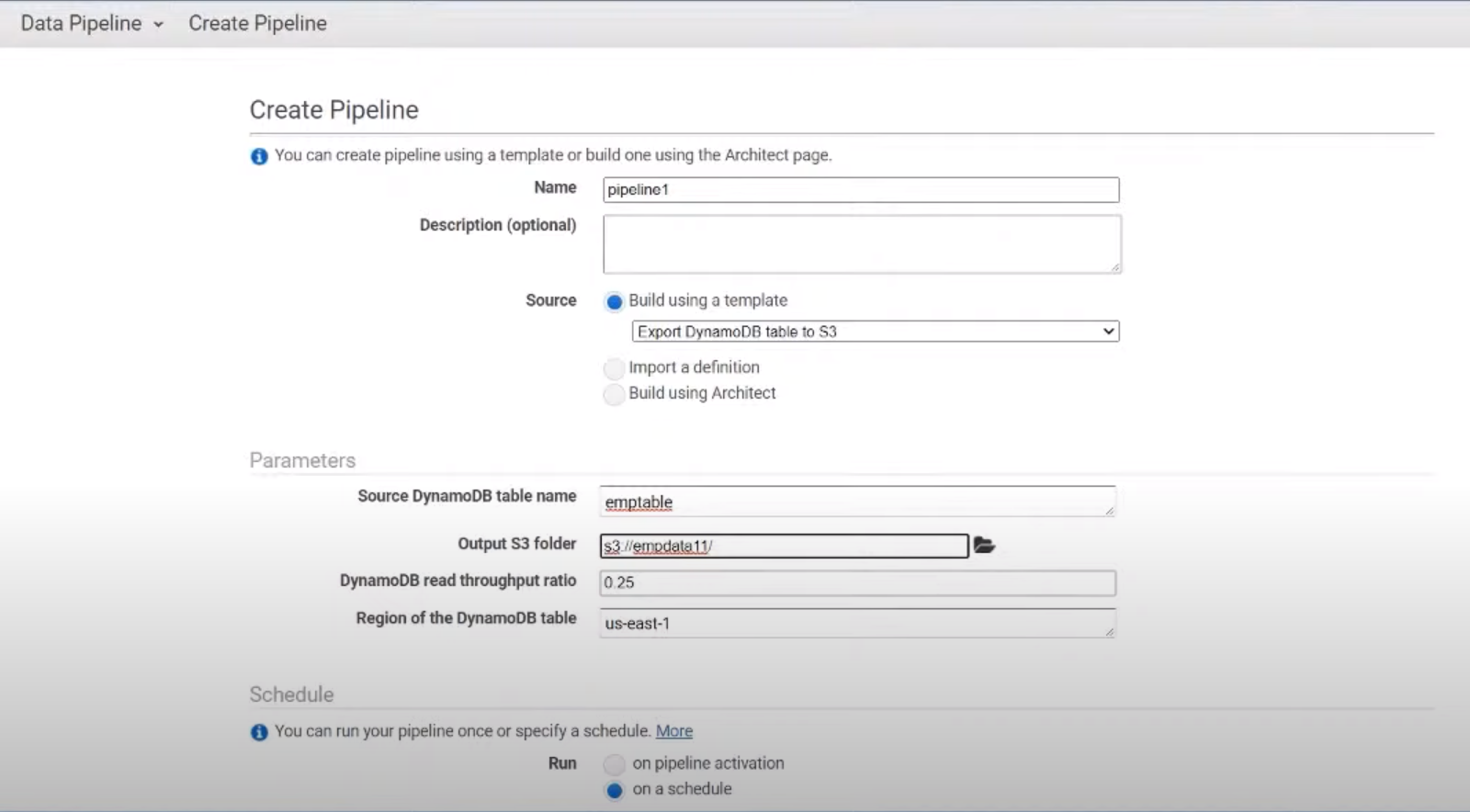
Step 5: Configure Components
- Configure the individual components of the pipeline by specifying the details such as input or output locations, resource requirements and processing logic.
Step 6: Schedule Pipeline Execution
- In this step, step up a schedule to a select pipeline to run at specific intervals or triggering it based on the predefined events.
Step 7: Activate Pipeline
- Now, activate the pipeline for initiating the workflow execution according to defined schedule or trigger conditions.
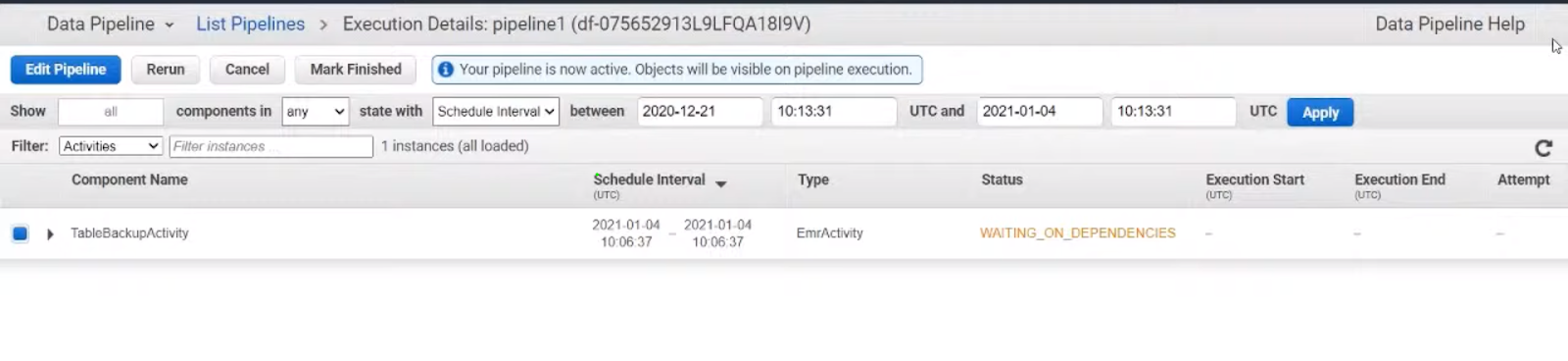
Step 8: Monitor Piepline Execution
- Creating and Running the DataPipeline has completed, now as a final step we have to monitoring the execution of the data pipeline using service such as AWS CloudWatch for collecting metrics and logs. These helps in taking appropriate actions in case of any issues or failures that encountered during pipeline execution.
Pricing of AWS Data Pipeline
The following table specifies the detailing of AWS Data Pipeline pricing:
|
Service
|
Description
|
Pricing
|
|
Data Pipeline
|
It is Orchestrating service for Data driven WorkFlow
|
Pay-as-you-go model
|
|
|
|
For Active Pipeline it charges $1/month
|
|
|
|
For On-premises Resource it charges $0.40/month
|
|
|
|
For Activity-runs it charges $0.005/minute
|
|
|
|
In Free-tier ( Initial 1 Year ) it offers 2,000 activity-run minutes per month for free.
|
Challenges Resolved With AWS Data Pipeline
Data is added at a rapid-fire pace. Data processing, storehouse, operation, and migration are getting complex and more time-consuming than they used to be in history. The data is getting complicated to deal with due to the below-listed factors.
- Bulk data getting generated which is substantially in raw form or is undressed.
- Different formats of data- the data being generated is unshaped. It’s a tedious task to convert the data to compatible formats.
- Multiple storehouse options there are a variety of data storehouse options. These include data storage or pall-grounded storehouse options like those of Amazon S3 or Amazon Relational Database Service( RDS).
Benefits/Advantages of Data Pipeline
Some of the advantages of AWS Data Pipeline are:
- Low Cost: AWS Pipeline pricing is affordable and billed at a low yearly rate. AWS free league includes free trials and $1,000 in AWS credits. Upon sign-up, new AWS guests admit the following each month for one time
- Easy to Use: AWS offers a drag-and-drop option for a person to design a channel fluently. Businesses don’t have to write a law to use common preconditions, similar to checking for an Amazon S3 train. You only have to give the name and path of the Amazon S3 pail, and the channel will give you the information. AWS also offers a wide range of template libraries for snappily designing channels.
- Reliable: AWS Cloud Pipeline is erected on a largely available, distributed structure designed for fault-tolerant prosecution of your events. With Amazon EC2, druggies can rent virtual computers to run their computer operations and channels. AWS Pipeline can automatically retry the exertion if there’s a failure in your exertion sense or sources. AWS Cloud Pipeline will shoot failure announcements via Amazon Simple announcement Service whenever the failure is not fixed.
- Flexible: AWS channel is flexible, and it can run SQL queries directly on the databases or configure and run tasks like Amazon EMR. AWS cloud channels can also help in executing custom operations at the associations ’ data centers or on Amazon EC2 cases, helping in data analysis and processing.
- Scalable: The inflexibility of the AWS channel makes them largely scalable. It makes recycling a million lines as easy as a single train, in periodical or resemblant.
Uses of AWS Data Pipeline
Use AWS Data Pipeline to record and manage periodic data processing jobs on AWS systems. Data pipelines have so much power that they can replace simple systems that may be managed by brittle, cron-grounded results. But you can also use it to make more complex, multi-stage data processing jobs.
Use Data Pipeline to:
- Move batch data between AWS factors.
- Loading AWS log data to Redshift.
- Data loads and excerpts( between RDS, Redshift, and S3)
- Replicating a database to S3
- DynamoDB backup and recovery
- Run ETL jobs that don’t bear the use of Apache Spark or that do bear the use of multiple processing machines( Pig, Hive, and so on).
AWS Data Pipeline – FAQs
Is AWS Data Pipline an ETL Tool?
Yes, AWS Data Pipeline is an ETL (Extract, Transform, Load ) tool that is used for orchestrating and automating data workflows.
How AWS Data Pipeline is different from AWS Glue?
AWS Data Pipeline is a workflow orchestration tool whereas AWS Glue is a fully managed ETL service with built-in data cataloging capabilities.
What are the examples of AWS Data Pipeline?
The Migration of data between Amazon S3 and Amazon Redshift, log processing with Amazon EMR, and data synchronization between on-premises and AWS Databases are the examples of AWS Data Pipeline.
How do I use AWS Data Pipeline?
You can use AWS Data Pipeline for defining and scheduling data driven workflows through AWS Management Console, CLI, AWS SDKs or Query APIs.
Share your thoughts in the comments
Please Login to comment...