PySpark – GroupBy and sort DataFrame in descending order
Last Updated :
20 Mar, 2023
In this article, we will discuss how to groupby PySpark DataFrame and then sort it in descending order.
Methods Used
- groupBy(): The groupBy() function in pyspark is used for identical grouping data on DataFrame while performing an aggregate function on the grouped data.
Syntax: DataFrame.groupBy(*cols)
Parameters:
- cols→ Columns by which we need to group data
- sort(): The sort() function is used to sort one or more columns. By default, it sorts by ascending order.
Syntax: sort(*cols, ascending=True)
Parameters:
- cols→ Columns by which sorting is needed to be performed.
- PySpark DataFrame also provides orderBy() function that sorts one or more columns. By default, it orders by ascending.
Syntax: orderBy(*cols, ascending=True)
Parameters:
- cols→ Columns by which sorting is needed to be performed.
- ascending→ Boolean value to say that sorting is to be done in ascending order
Example 1: In this example, we are going to group the dataframe by name and aggregate marks. We will sort the table using the sort() function in which we will access the column using the col() function and desc() function to sort it in descending order.
Python3
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg, col, desc
spark = SparkSession.builder.appName("GeeksForGeeks").getOrCreate()
simpleData = [("Pulkit","trial_1",32),
("Ritika","trial_1",42),
("Pulkit","trial_2",45),
("Ritika","trial_2",50),
("Ritika","trial_3",62),
("Pulkit","trial_3",55),
("Ritika","trial_4",75),
("Pulkit","trial_4",70)
]
schema = ["Name","Number_of_Trials","Marks"]
df = spark.createDataFrame(data=simpleData, schema = schema)
df.groupBy("Name") \
.agg(avg("Marks").alias("Avg_Marks")) \
.sort(col("Avg_Marks").desc()) \
.show()
spark.stop()
|
Output:
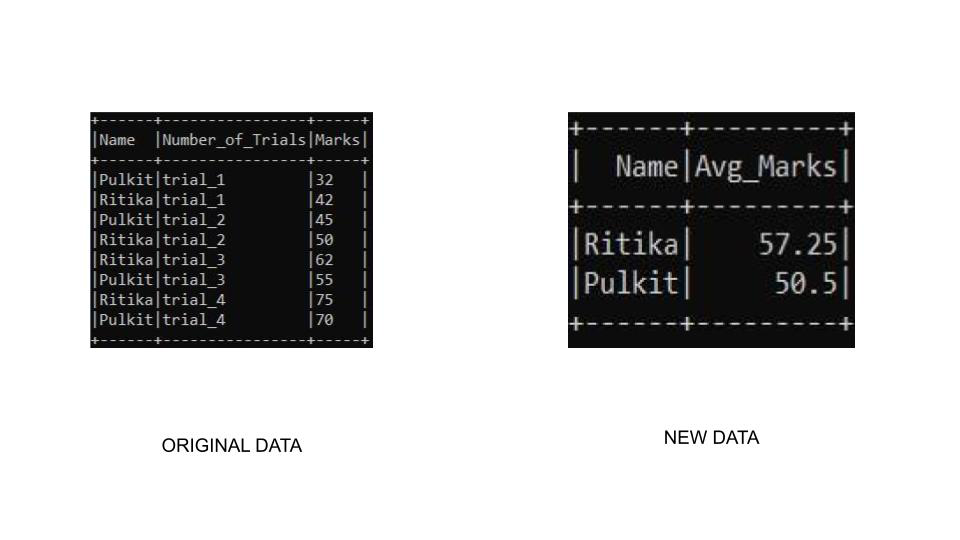
Example 2: In this example, we are going to group the dataframe by name and aggregate marks. We will sort the table using the sort() function in which we will access the column within the desc() function to sort it in descending order.
Python3
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg, col, desc
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
simpleData = [("Pulkit","trial_1",32),
("Ritika","trial_1",42),
("Pulkit","trial_2",45),
("Ritika","trial_2",50),
("Ritika","trial_3",62),
("Pulkit","trial_3",55),
("Ritika","trial_4",75),
("Pulkit","trial_4",70)
]
schema = ["Name","Number_of_Trials","Marks"]
df = spark.createDataFrame(data=simpleData, schema = schema)
df.groupBy("Name") \
.agg(avg("Marks").alias("Avg_Marks")) \
.sort(desc("Avg_Marks")) \
.show()
spark.stop()
|
Output:
Example 3: In this example, we are going to group the dataframe by name and aggregate marks. We will sort the table using the orderBy() function in which we will pass ascending parameter as False to sort the data in descending order.
Python3
from pyspark.sql import SparkSession
from pyspark.sql.functions import avg, col, desc
spark = SparkSession.builder.appName("Student_Info").getOrCreate()
simpleData = [("Pulkit","trial_1",32),
("Ritika","trial_1",42),
("Pulkit","trial_2",45),
("Ritika","trial_2",50),
("Ritika","trial_3",62),
("Pulkit","trial_3",55),
("Ritika","trial_4",75),
("Pulkit","trial_4",70)
]
schema = ["Name","Number_of_Trials","Marks"]
df = spark.createDataFrame(data=simpleData, schema = schema)
df.groupBy("Name")\
.agg(avg("Marks").alias("Avg_Marks"))\
.orderBy("Avg_Marks", ascending=False)\
.show()
spark.stop()
|
Output:
Share your thoughts in the comments
Please Login to comment...